
Your AI setup is quietly rotting
What an automated health check found hiding in 127 lines of configuration


I ran the audit expecting a clean result.
15 Claude Code production skills, all reviewed within the last 2 days. Every quality gate passing. Error handling tables added, retry loops capped, shared references consolidated. I’d spent the previous week building a system that maintains my skills, and the skills were in the best shape they’d ever been.
So I built something to check the layer underneath: the configuration, the memory, the rules, the always-loaded context that every skill shares. The environment they all run in.
The score came back 6 out of 10 on memory health. Below threshold. The memory system I thought was well-organised was carrying 10,718 characters of inlined content in a file designed to be an index.
That landed. A week of careful skill maintenance. Every quality gate green. And the shared foundation underneath all of it, the files Claude reads before I type a single word, scored below the minimum for a healthy environment. I’d been polishing the tools while the workbench was quietly falling apart.
You know the feeling.
Mid-session. You ask Claude to follow a rule you know is in the config. It doesn’t. You rephrase and it works on the second try. You lose 90 seconds and blame the phrasing. Or compaction triggers earlier in the conversation than it used to, and you start a fresh session instead of investigating why. Or the output feels slightly off in a way you can’t articulate: not wrong, exactly, but less sharp than you remember it being 3 weeks ago.
You check the obvious things. The skills work. The prompts are fine. The MCP servers connect. Everything passes. So you attribute the friction to the model, or the complexity of the task, or the context window just being what it is.
You don’t check the environment. You set it up. It worked. Why would anything have changed?
But it did change. Every decision you baked into a memory file, every tool you added to the stack, every rule you wrote without path triggers: each one added to the always-loaded context. Each change was individually reasonable. Together, they compounded into a context budget you never consciously chose. And because the degradation is gradual, there’s no moment it crosses a threshold. No error. No warning. Just sessions that are subtly, consistently less effective than they could be. You adapt. You learn to rephrase prompts that should work the first time. You accept earlier compaction as normal. You lower your expectations without realising you’re doing it.
My memory index was 127 lines long. It was supposed to be 33.
Somewhere over the past 6 weeks, the index had become the knowledge base itself: resolved decisions, workflow habits, tool configurations, gotchas, course completion status. All inlined directly in the file that Claude reads before every conversation. A memory index should be a directory: short entries pointing to properly typed files. User preferences in one file. Project context in another. Reference material in a third. The index holds the pointers. Mine was holding everything.
Cost: 2,680 tokens. Every session. Before I type a word. That instruction I rephrased on Tuesday? It was buried under 2,680 tokens of inlined memory content, all of it loaded before I’d even started the conversation. The same information, extracted into 24 linked files with a clean 33-line index, costs 665 tokens. That’s 2,015 tokens of invisible tax on every conversation for weeks.
Once I saw the memory bloat, the rest unravelled quickly. I found the same retry instruction in the project config and the memory system. Presentation theme IDs duplicated in 2 files. Playwright setup details in the memory system and in a rules file. The duplication wasn’t deliberate. It was the natural result of learning things in context. You discover a gotcha during a session, you write it down in the nearest file, you move on. You don’t cross-reference against the 3 other files that might already contain the same instruction. Over weeks, the copies accumulate. And they diverge. When you update one copy and forget the other, Claude reads both versions and follows whichever it encounters last. That vague inconsistency you can never quite pin down? This is one of the places it lives.
Then the staleness. 2 weeks earlier I’d dropped X from my content strategy. I’d updated the skills, changed the workflow. But the project config and a content rule still described the old workflow. A rule file pointed to a tools directory that had moved months ago. Nobody had noticed. I’d been working in this environment for weeks, every session reading instructions about a platform I’d consciously decided to abandon. The config was telling Claude one thing. My skills were telling it another. And I was getting output that split the difference in ways too subtle to trace back to a stale reference I’d forgotten existed.
Then the context waste. 4 skills with significant side effects were auto-loading their descriptions into every session so Claude could decide whether they were relevant. They never were. These skills only run when called explicitly. Hiding them from auto-triggering saved roughly 1,800 characters per session: context that existed for no reason except that I hadn’t thought to turn it off.
The combined fix took one session. Memory restructured: 127 lines to 33. 24 properly typed files, zero orphans. 3 duplicated instructions removed. 2 stale references corrected. 4 side-effect skills hidden from auto-triggering. Total always-loaded context reduced by approximately 2,400 tokens.
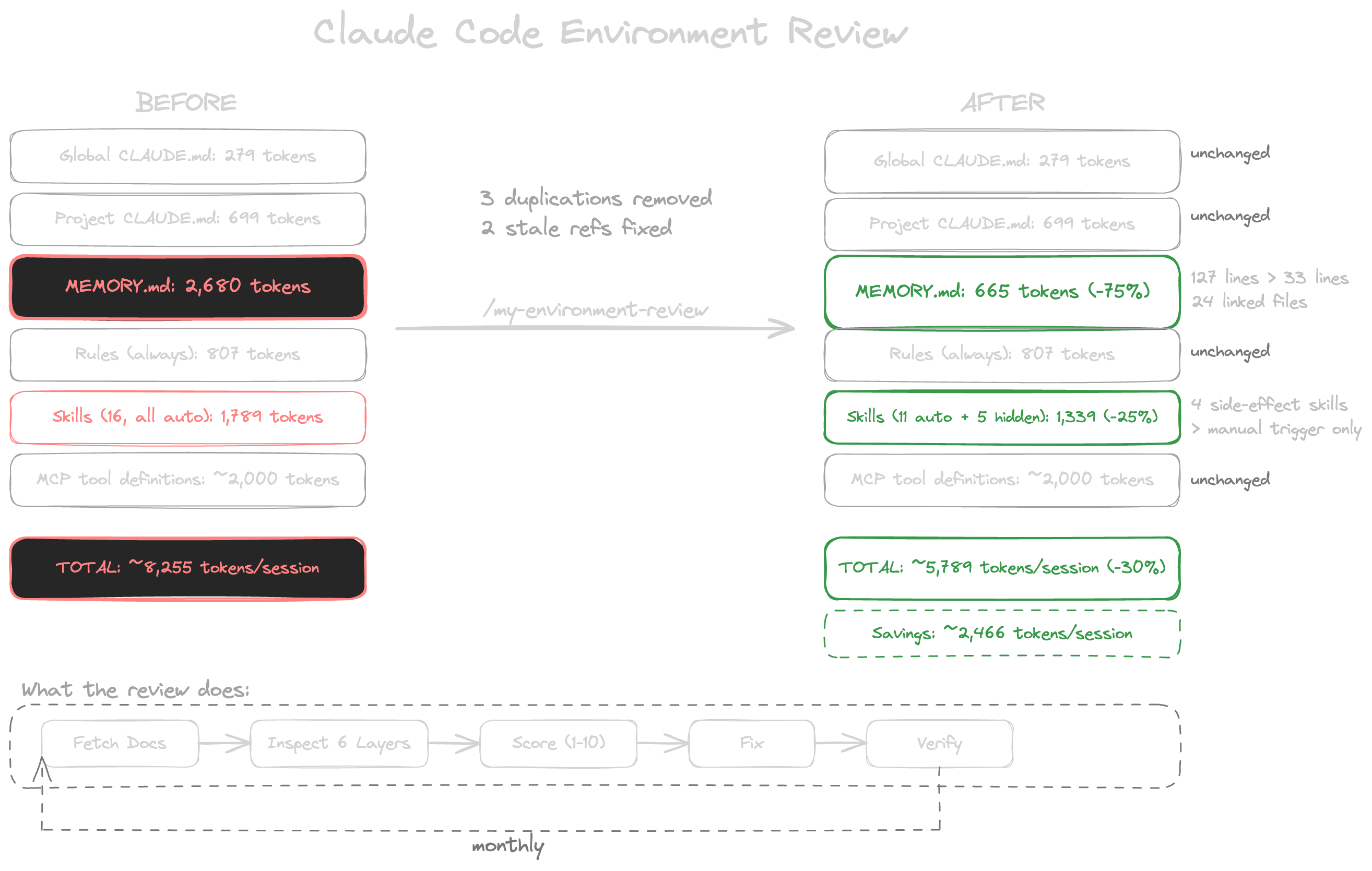
The tool that found all of this is a single skill. It fetches Anthropic’s current documentation on every run, walks every configuration layer, cross-references every file, counts the tokens, scores the environment against a rubric, and implements the prioritised fixes. One command. Full cycle: inspect, score, report, fix, verify. The same principle applies to any AI workflow: the agent that builds something shouldn’t be the only one reviewing it.
If you want to build your own, start with what’s always loaded. Count the characters in every file that loads at session start. Divide by 4 for a rough token estimate. That’s your entry tax. If your memory index has crossed 50 lines, content has leaked into it that belongs in linked files. If the same instruction lives in 2 places, one will drift. If a skill with side effects can auto-trigger, it will burn context every session deciding not to run.
I can’t tell you what those 2,400 tokens were actually costing me in output quality. There’s no A/B test for “what would this session have been like with a leaner context?” No metric that says “Claude followed your instructions 12% less often because the memory file was drowning them out.”
Previously, I wrote about building the system that maintains your skills. This week’s discovery was one layer deeper. I’d spent a week fine-tuning every skill in the library while the shared infrastructure underneath carried 2,400 tokens of dead weight. The skills passed their quality gates. The environment they ran in scored a 6. I’d been maintaining the surface while the foundation accumulated every decision, every workaround, every preference I’d ever written down, all of it loaded into every session, all the time.
Build the baseline. Audit the foundation, not just the tools sitting on it.
Configuration debt doesn’t announce itself. It just becomes the normal you’ve already adapted to.