
Stop Building Skills. Start Building the System That Maintains Them.
What happens when you point Claude Code's own tooling at the skills you've built


I have 12 production skills in Claude Code. They handle everything: weekly content pipelines, image generation, video production, anti-AI text auditing, and prompt engineering. Together, they run a content operation that would take a small team to manage manually.
They were also quietly falling apart.
Not catastrophically. The kind of decay you don’t notice until you do: an engagement gate with no retry cap that could loop forever. An inline checklist duplicated across 3 skills, slowly drifting out of sync. Error handling that covered only the happy path. A reference file that still said “3 images per week” when the workflow had evolved to 4.
I didn’t find these problems by reading through my skills one afternoon. I built a system that found them for me, told me exactly what was wrong, and fixed them. Then I built the system that prevents them from happening again.
Here’s how.
The architecture has 3 components. Each one does a specific job. Together, they create feedback loops that compound over time.
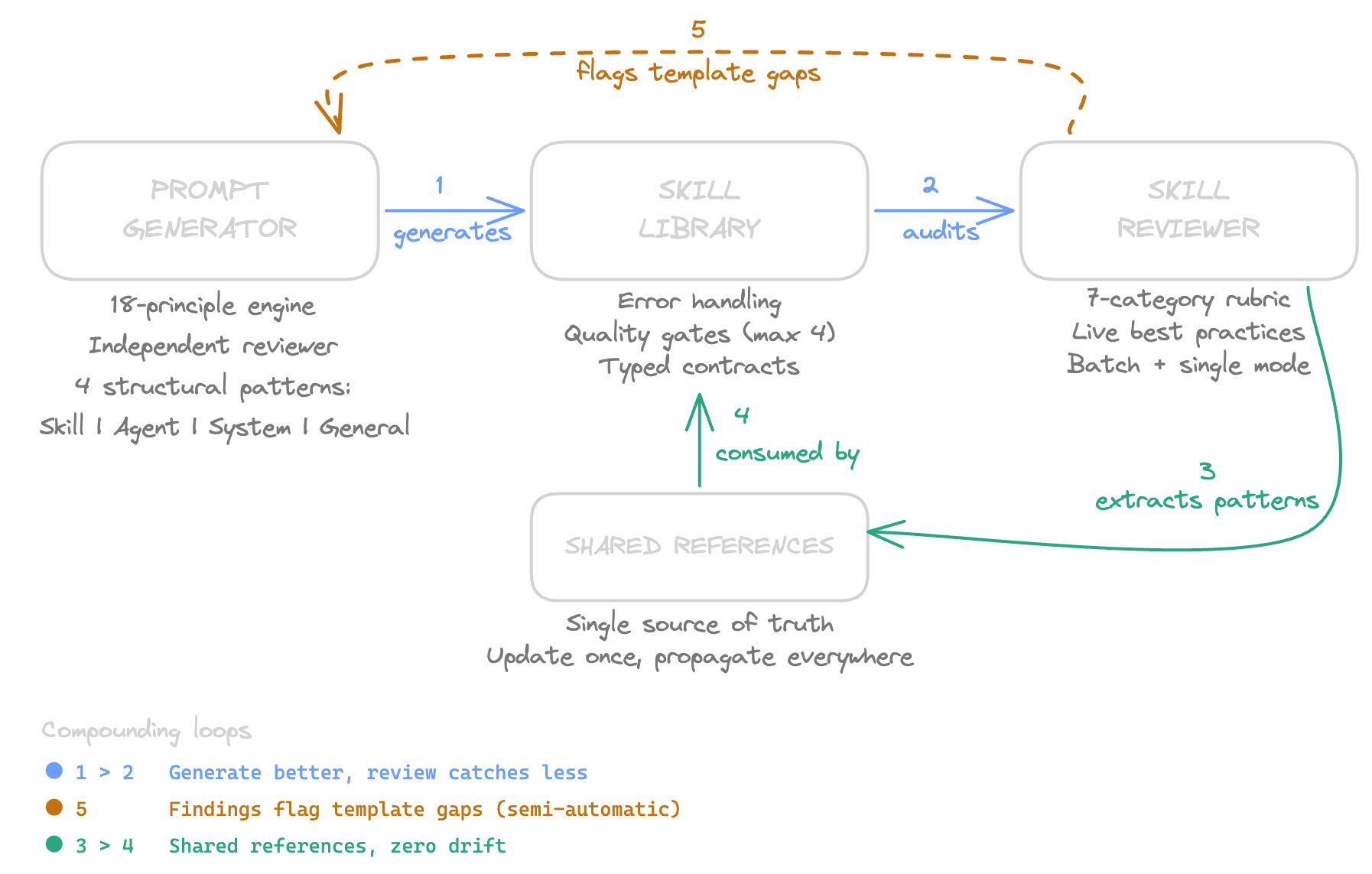
Component 1: The Prompt Generator. A skill that builds other skills. It encodes Anthropic’s prompt-engineering best practices into a repeatable workflow: interview the user, classify the prompt type, select a structural pattern, generate the skill, run a self-evaluation against an 18-principle engine, then dispatch an independent reviewer agent to score clarity, completeness, and structure. The reviewer has no context from the generation process. It evaluates the prompt on its own merits. Minimum scores: 8/10 across all 3 dimensions.
This means every new skill starts at a high baseline. Error handling, typed contracts, quality gates, progressive disclosure: they’re baked into the generation templates, not left to whatever habits the session happens to have.
Component 2: The Skill Reviewer. A skill that audits other skills. It fetches the latest Anthropic documentation on skill building (live, every time, so the rubric stays current), reads the entire skill folder, and scores it against 7 categories: trigger precision, instruction clarity, context efficiency, workflow design, quality assurance, error handling, and integration. Each category has score bands (1-10), a minimum threshold, and a checklist of specific items to verify.
It comes in 2 modes.
/skill-review blog-article reviews a single skill interactively: scorecard, recommendations, then “want me to fix these?”
/skill-review-all dispatches reviews for every skill in parallel, aggregates the scores into a summary table sorted worst-to-best, and presents the top 5 fixes by priority. One command to audit your entire skill library.
Component 3: Shared References. Files that multiple skills consume from a single location. The most impactful example: I had an anti-AI audit checklist (13 banned patterns, 7 writing-style sections to check, a cold-read pass) duplicated inline across 3 content skills. Each copy was roughly 35 lines. When I updated the banned pattern list, I had to remember to edit all 3 skills. I didn’t always remember.
Now there’s one file: anti-ai-audit.md. 5 skills reference it. Zero copies to maintain. When I add a new banned pattern, every skill picks it up on the next invocation.
These 3 components create feedback loops that get stronger over time.
Loop 1: Generate better, review catches less. When I batch-reviewed all 12 skills, error handling was the systemic weakness: 10 out of 10 skills had no error handling section. That pattern is now encoded in the prompt generator’s structural templates. The next skill I build won’t have that gap. The reviewer will find fewer issues because the generator already prevents them.
Loop 2: Review findings improve generation. Every cross-cutting pattern the reviewer discovers (unbounded retry loops, missing output contracts, and inline duplication) feeds back into the generator’s templates and the reviewer’s rubric. The rubric gets smarter with each batch review. The generator inherits those lessons. Both tools evolve from real findings, not theoretical best practices.
Loop 3: Shared references eliminate drift. When the reviewer extracts a duplicated pattern into a shared reference file, it doesn’t just fix the current problem. It prevents the problem from recurring. The anti-AI audit checklist, the principles engine, and the structural patterns: they’re each maintained in one place and consumed by many skills. Update once, propagate everywhere.
The practical impact from a single session of building and running this system:
I reviewed all 12 of my production skills against Anthropic’s current best practices. The reviewer found that error handling was missing across the board, quality gate retry loops were unbounded (burning a lot of tokens on infinite revision cycles), anti-AI audit checklists were duplicated in 3 places, and orchestrated-mode contracts between skills were informal (prose descriptions instead of typed field definitions).
The fixes: error handling tables added to 10 skills. All quality gates are capped at 4 iterations. The anti-AI audit was consolidated into a single shared file, saving roughly 128 lines of duplicated code (context engineering is underrated!). Typed return format tables have been added to every skill with an orchestrated mode. Negative triggers were added to 7 skill descriptions to prevent false activation.
One optimisation deserves specific mention. My article quality gate dispatched 2 agents in parallel for every draft: an advocate and a critic. The advocate’s job was to provide a counterpoint to the harsh critic. But since my articles consistently passed with scores well above the thresholds, the advocate was adding roughly 50% more tokens to the most expensive quality check for marginal value. The fix: run the critic first. Only dispatch the advocate if any score lands within 1 point of the threshold (a borderline call where a second opinion genuinely matters). Clear passes and clear fails skip the advocate entirely. Same quality architecture, roughly 40-50% fewer tokens on the happy path.
Total context savings across all skills: approximately 300 lines eliminated. 2 unused skills deleted. 2 new meta-skills created. Every skill now carries a last-reviewed date in its YAML frontmatter, automatically updated by the reviewer after each audit.
If you want to build this for your own skill library, here’s the sequence.
Start with the reviewer, not the generator. You probably already have skills. Audit what exists before building new ones. The reviewer’s rubric gives you a baseline score and surfaces the systemic patterns (issues that affect multiple skills). Fix the cross-cutting problems first: they have the highest leverage.
Build the rubric from first principles. Think about a skill as a system. It has a boundary (triggers), internal logic (instructions), resources (context window), a process (workflow), feedback loops (quality gates), resilience (error handling), and an environment (integration with other skills). Score each dimension. Set minimum thresholds based on how much each one affects output reliability. My thresholds: instruction clarity and workflow design at 8/10 (they directly impact output quality), trigger precision and context efficiency at 7/10, quality assurance at 7/10, error handling and integration at 6/10.
Fetch current best practices live. Anthropic’s documentation evolves. Skills that were well-structured 3 months ago might miss newly recommended patterns. The reviewer web-searches for the latest guidance on every run and uses it to supplement the rubric. Cached docs are the fallback, not the default. Point Claude to its own documentation.
Extract shared patterns immediately. When the reviewer finds the same checklist, template, or protocol duplicated across skills, extract it to a shared reference file in the same session. Don’t make a note to do it later. The longer duplicates exist, the more they drift.
Build the generator after your first batch review. By then, you know what patterns every skill needs (because the reviewer told you what was missing). Encode those patterns into the generator’s structural templates. Every new skill inherits the lessons from your existing library’s failures.
Add last-reviewed to your YAML frontmatter. One field, one date. The reviewer updates it after each audit. When you run a batch review in a month, you can see which skills haven’t been touched and whether new best practices have emerged that your older skills don’t follow.
The meta-insight isn’t about Claude Code, skills, or rubrics. It’s about where you invest your engineering effort.
Most people build tools and move on. The tools work until they don’t, and then you’re debugging a skill you wrote 3 months ago, trying to remember why you structured it that way, discovering it references a file that’s been renamed, and realising the quality gate you thought was running has been silently skipping for weeks.
The highest-leverage work isn’t building the 13th skill. It’s building the infrastructure that keeps the first 12 from degrading.
A generator that encodes your standards into every new skill. A reviewer who catches drift before it compounds. Shared references that update once and propagate everywhere.
You didn’t just build skills. You built the system that maintains them.
That’s what compounds.